
28 Mar 2023 Cómo usar OpenRouteService y Overpass en R
Con la evolución del sector GeoTech, obtener información del territorio es cada vez más fácil. Pero, para conseguir esta información es necesario conocer las herramientas que nos facilitan el acceso. Es por esto, que en este post detallaremos cómo usar OpenRouteService y Overpass en R para la extracción de datos del territorio.
El uso de herramientas como OpenRouteService y Overpass nos pueden ayudar a capturar la información que hay almacenada en OSM. No entraremos en detalle sobre las diferencias y descripciones de cada una de ellas. En caso de que necesites más información sobre Overpass, puedes consultar el post de Toni Hernández donde nos detalla la extracción de datos inteligente con Overpass.
En lo que respecta a ORS, es un servicio de enrutamiento en línea (routing) y de análisis de geodatos de código abierto y es mantenido por el Humanitarian OpenStreetMap Team (HOT). Ofrece una amplia gama de funciones, que incluyen cálculo de rutas, tiempo y distancia de viaje, geocodificación, isócronas y análisis de accesibilidad.
Para ver cómo funcionan estas dos librerías nos propondremos como objetivo obtener los servicios que se encuentran en un área en concreto de Barcelona. Así que ten preparado RStudio porque empezamos.
Cargamos las librerías
Estas las usaremos para el mapa y la transformación de geometrías:
library(sf)
library(leaflet)
Las siguientes son las librerías de Overpass API y ORS:
library(overpass)
library(openrouteservice)
Y, por último, la librería para obtener las coordenadas, a partir de una dirección:
library(tmaptools)
Overpass
En este apartado veremos cómo usar Overpass. Lo primero que se va a hacer es construir la consulta, que puedes construir en: Overpass-turbo.
Construir la consulta
osmcsv <- '[out:csv(::id, ::lat, ::lon, "amenity", "shop", "railway", "name"; true “,”)];
(area[name="España"]->.country;
area[name="Barcelona"][admin_level=8]->.city;
node(area.city)(area.country)[railway=station];
node(area.city)(area.country)[shop=supermarket];
node(area.city)(area.country)[amenity=cafe];
node(area.city)(area.country)[amenity=restaurant];
node(area.city)(area.country)[amenity=school];
);
out;'Como puedes ver, en la primera línea se especifican los atributos que queremos extraer de la consulta. Los tres primeros (id, lat, lot) deben de ser precedidos por dos veces dos puntos (::), ya que se trata de atributos especiales. Al final de la línea, indicamos la separación que queremos. Si no ponemos nada, por defecto siempre será ‘\t‘.
En la segunda y tercera línea se filtra por país y ciudad, mientras que en el resto de líneas se detallan aquellos servicios que se quieren extraer de Barcelona. Al ser múltiples nodes, los tenemos que encapsular dentro de dos paréntesis.
Por último, con out se indica el final de la consulta.
Extracción y visualización general de los datos
Lo siguiente será extraer los datos de la consulta con:
query <- overpass_query(osmcsv)Para este ejercicio se ha decidido guardar la consulta en un fichero .txt, para así no tener que realizar otra petición a la API de Overpass. También se podría hacer directamente read.table(), en el caso de que se quiera trabajar directamente con la información extraída sin guardar.
write(query, "query.txt")A continuación, cargamos los datos y vemos por encima la información.
dfOPS <- read.csv("query.txt", sep= ",")
colnames(dfOPS)
head(dfOPS)
summary(dfOPS)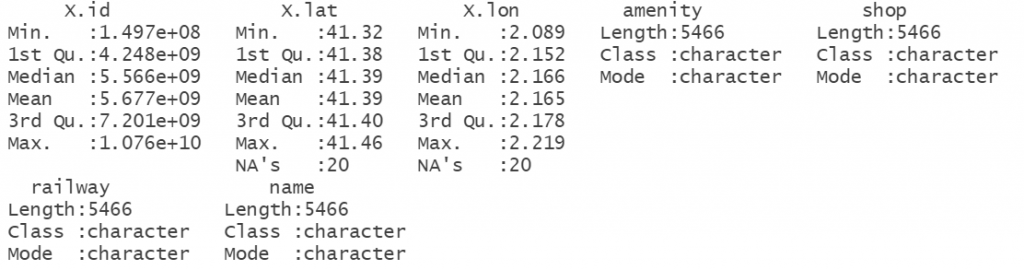
str(dfOPS)
Se puede ver como se han cargado los datos correctamente. Tenemos un total de 5.466 observaciones, con 7 características. También se puede detectar la presencia de valores nulos en lat y lon. A continuación, eliminaremos estas observaciones.
dfOPS <- dfOPS[!is.na(dfOPS$X.lat),]Seguidamente, se crea una nueva columna que englobe los tipos de servicios para así poder eliminar las columnas de amenity, shop y railway. Finalmente, normalizamos el nombre de las variables.
dfOPS$service <- ifelse(dfOPS$amenity == "" & dfOPS$shop == "", dfOPS$railway,
ifelse(dfOPS$amenity == "" & dfOPS$railway == "", dfOPS$shop, dfOPS$amenity))
dfOPS[c("amenity", "shop", "railway")] <- NULL
names(dfOPS) <- c("id", "lat", "lon", "name", "service")Veamos como queda el data frame.
head(dfOPS)
Parece que los datos ya empiezan a estar más limpios y ordenados. No obstante, name todavía tiene valores nulos.
length(dfOPS$name[dfOPS$name == ""])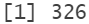
Hay un total de 326 observaciones sin nombre que pasaran a llamarse N/A.
dfOPS$name[dfOPS$name == ""] <- "N/A"Una vez limpiada la información, veamos qué distribución tenemos de servicios.
table(dfOPS$service)
Se puede ver como en Barcelona, lo que más abunda, según los datos de OSM, son los restaurantes, las cafeterías y los supermercados. Pero, también hay un buen número de escuelas y estaciones. A continuación, se obtendrán las coordenadas de la dirección de la Sagrada Familia, con lo que crearemos un punto y un buffer de 500 m de radio alrededor del punto.
address <- geocode_OSM("Sagrada Familia")
point <- st_sf(geometry = st_sfc(st_point(c(address$coords[[1]], address$coords[[2]]))), crs = 4326)
buffer <- st_buffer(point, dist = 500)Analicemos las líneas anteriores. Se ha creado un punto, a partir de las coordenadas dadas por address y seguidamente hemos creado un buffer. Podemos detallar que:
– Con st_sf() se crea un objeto de datos espaciales en formato simple feature, que contendrá la geometría del punto, además de otra información. Al final de la línea, le detallamos el CRS 4326.
– Con st_sfc() se crea una colección de geometrías simples. En este caso de un solo punto.
– Con st_point() se crea el punto a partir de las coordenadas proporcionadas.
– Con st_buffer() se crea el área, a partir del punto que se ha especificado, con 500 m de radio. En este caso, no ha hecho falta transformar las coordenadas a UTM, ya que esta función es capaz de realizar la operación buffer de manera eficiente y precisa con coordenadas WGS84.
Veamos como ha quedado el buffer creado con leaflet.
leaflet() %>%
addTiles() %>%
addPolygons(data=buffer)El siguiente paso será transformar los servicios a simple feature, para así obtener aquellos que intersequen con el área buffer.
services <- st_as_sf(df, coords = c("lon", "lat"), crs = 4326)
poisIn <- st_intersection(buffer, services)Veamos con leaflet las dos capas: los puntos (servicios) y el polígono (área) en el mismo mapa.
leaflet() %>%
addTiles() %>%
addMarkers(data=poisIn,
clusterOptions = markerClusterOptions(),
popup = paste("",poisIn$service," "," ",poisIn$name)) %>%
addPolygons(data=buffer)Se puede ver como la operación se ha realizado correctamente.
A continuación, con prop.table() veremos la proporción de servicios que tenemos alrededor de la Sagrada Familia en un radio de 500 m.
round(prop.table(table(poisIn$service))*100, 2)
La proporción de servicios que tenemos en la Sagrada Familia es bastante parecida a la de Barcelona en general.
El potencial de Overpass
Llegados a este punto, hemos podido ver el potencial que nos brinda Overpass para extraer datos del territorio. Al haber cargado todos los servicios directamente de la ciudad, tenemos una capa de puntos con la que podemos trabajar cómodamente.
Es decir, podríamos tener otra capa de puntos que representaran, por ejemplo, pisos en alquiler y ver qué servicios se encuentran dentro del área de influencia de cada inmueble. Esta operación la podríamos hacer sin ningún tipo de límite de request por segundo, ya que los datos de Barcelona ya los habríamos descargado.
OpenRouteService
En este apartado, veremos cómo usar OpenRouteService. Con ORS se pueden obtener los Puntos de Interés (POIS), a partir de unas coordenadas en concreto, donde se generará un buffer. Este servicio tiene ciertas limitaciones como, por ejemplo, el radio máximo que podemos crear para nuestra área es de 2 km; y el total de peticiones que se pueden hacer es de 40 por minuto y 2.500 por día. En caso de que se quiera ir más allá, se puede instalar el backend de ORS. Para más información sobre las restricciones, consulta su página.
Bien, para empezar a utilizar este servicio, se creará una lista con los servicios por los que se quieren filtrar los datos. En este caso, serán los mismos servicios que en el caso anterior.
list <- c("cafe", "restaurant", "school", "station", "supermarket")Definimos el data frame donde pondremos los servicios sin filtrar.
dfORS = data.frame()A continuación, se creará el objeto geometry donde se representará el punto con las coordenadas de la dirección de la Sagrada Familia y el buffer generado con un radio de 500m.
geometry <- list(
geojson = list(
type = "Point",
coordinates = c(adress$coords[1], adress$coords[2])
),
buffer = 500
)Seguidamente, se obtendrán los puntos de interés que se encuentran dentro de nuestra área creada en geometry. Si te has dado cuenta, no usamos el filtro de category_ids, ya que queremos ver primero qué servicios nos da este servicio primero. En caso de que quieras especificar las categorías, tienes los códigos en este repositorio.
dfPois <- ors_pois(
request = 'pois',
geometry = geometry,
limit = 2000,
sortby = "distance",
filters = list(
wheelchair = "yes"
),
output = 'sf'
)Un detalle que le aporta valor a este servicio es que podemos especificar que queremos aquellos servicios adaptados para gente en silla de ruedas. Por lo tanto, es una buena herramienta para medir la accesibilidad.
Veamos el resultado de nuestra query.
head(dfPois)
El atributo de category_ids tiene almacenado listas donde se encuentran los diferentes tags. Por lo tanto, está compuesto por diferentes niveles. Seguidamente, extraeremos el nombre que corresponde a cada servicio y lo pondremos en un nuevo data frame.
for (i in dfPois$category_ids){
if (typeof(i[[1]][1]) == "list"){
output = i[[1]][[1]][1]
} else {
output = i[[1]][1]
}
dfORS = rbind(dfORS, output)
}
colnames(dfORS)<-c("Services")
round(prop.table(table(dfORS$Services))*100, 2)A continuación, se mostrarán los diferentes servicios, sin filtrar, que hay en nuestra zona.
round(prop.table(table(dfORS$Services))*100, 2)
De los servicios que hemos obtenido como resultado, calcularemos el total que hay en cada uno de ellos.
elements <- aggregate(dfORS$Services, by=list(Category=dfORS$Services), FUN= length)Por último, podemos sacar una puntuación de 0 a 10 para ver la valoración de nuestra zona. Para este ejercicio pondremos unas condiciones simples. Es decir, si el servicio que se encuentra en la lista que hemos definido al principio, se encuentra entre los servicios extraídos de la consulta, añadiremos una puntuación. Si este servicio está presente más de dos veces, la puntuación será de dos puntos, de lo contrario será de un punto.
myList <-list()
total <- 0
totalQuant <- 0
for (i in 1:nrow(elements)){
element <- as.character(elements[i, 1])
quantity <- elements[i, 2]
if(element %in% list){
totalQuant <- totalQuant + quantity
myList[[element]] <- quantity
if (quantity >= 2){
total <- total + 2
}
else {
total <- total + 1
}
}
}La puntuación obtenida es de:
print(total)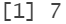
Por lo que respecta a la distribución de los servicios:
prop.table(unlist(myList)) * 100
A continuación, se creará un data frame a partir de las filas filtradas por los servicios obtenidos anteriormente. Este paso nos lo podemos ahorrar si al principio filtramos los datos por las categorías ya filtradas.
dfToMap <- data.frame()
for (i in 1:nrow(dfPois)){
categoryID <- dfPois$category_ids[[i]]
if (is.list(categoryID)){
if (categoryID[[1]][[1]] %in% list){
dfToMap = rbind(dfToMap, dfPois[i, ])
}
} else {
if (categoryID %in% list){
dfToMap = rbind(dfToMap, dfPois[i, ])
}
}
}Mostramos el resultado en un mapa con leaflet.
Tal como podemos ver en el mapa, el número de servicios que son accesibles para personas en sillas de ruedas es mucho más reducido que el resultado anterior.
Conclusión
En este post hemos podido ver cómo extraer datos del territorio con OpenRouteService y Overpass en R de manera fácil y rápida. Las herramientas como R, ORS y Overpass nos ayudan a la extracción de datos de forma eficaz. Solamente hace falta un poco de imaginación y saber mínimamente cómo hacer una consulta para enriquecer tu proyecto o cualquier análisis que te hayas dispuesto a realizar.
Si te ha gustado el post, te recomendamos que te suscribas a esta página y mires el programa de cursos y el Máster profesional en SIG. Aventúrate en el mundo de los datos espaciales y aprende a extraer la historia que se esconde tras ellos.