13 Sep 2017 Visualización y gestión de grandes volúmenes de datos en un cliente web. El proyecto de Mosquito Alert
El contexto
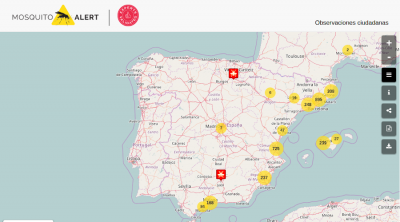
Desde 2016 en el Servicio de SIG y Teledetección (SIGTE) participamos en el proyecto Mosquito Alert (http://mosquitoalert.com). El proyecto se define como un observatorio de ciencia ciudadana para la vigilancia y control de mosquitos vectores de enfermedades en áreas urbanas. Distintas tecnologías interactúan con el fin de poder detectar, analizar y gestionar mejor las poblaciones especialmente problemáticas de mosquitos (como el mosquito tigre y el de la fiebre amarilla).
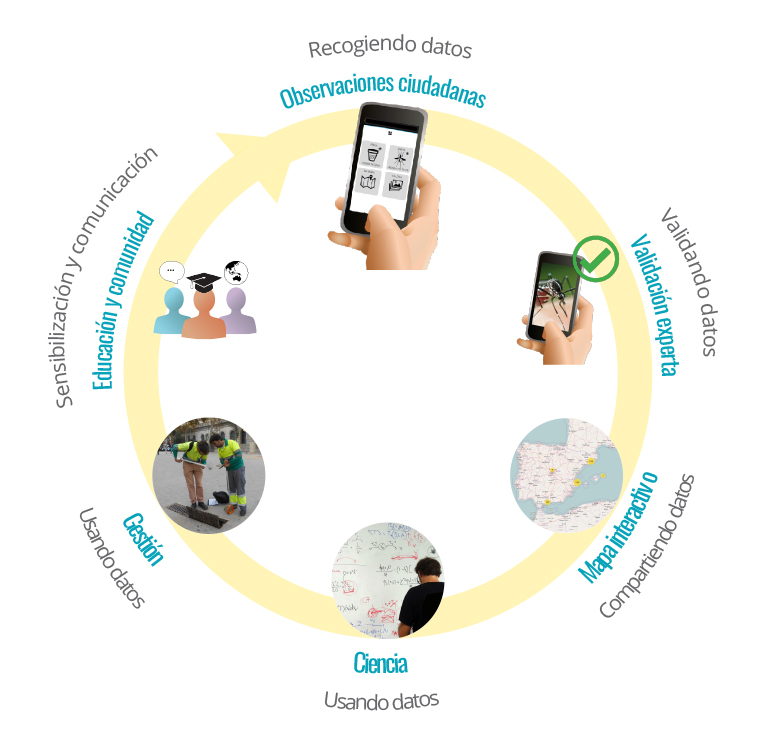
Esquema general del proyecto. Fuente: Web de MosquitoAlert (www.mosquitoalert.com). Más información en http://www.mosquitoalert.com/proyecto/que-es-mosquito-alert/.
Nuestra labor en este proyecto consiste en la creación del mapa interactivo que permite visualizar los datos recogidos por los ciudadanos (observaciones ciudadanas validadas por expertos), así como generar mapas personalizados y enviar notificaciones a los usuarios (a partir de un acceso restringido para gestores).
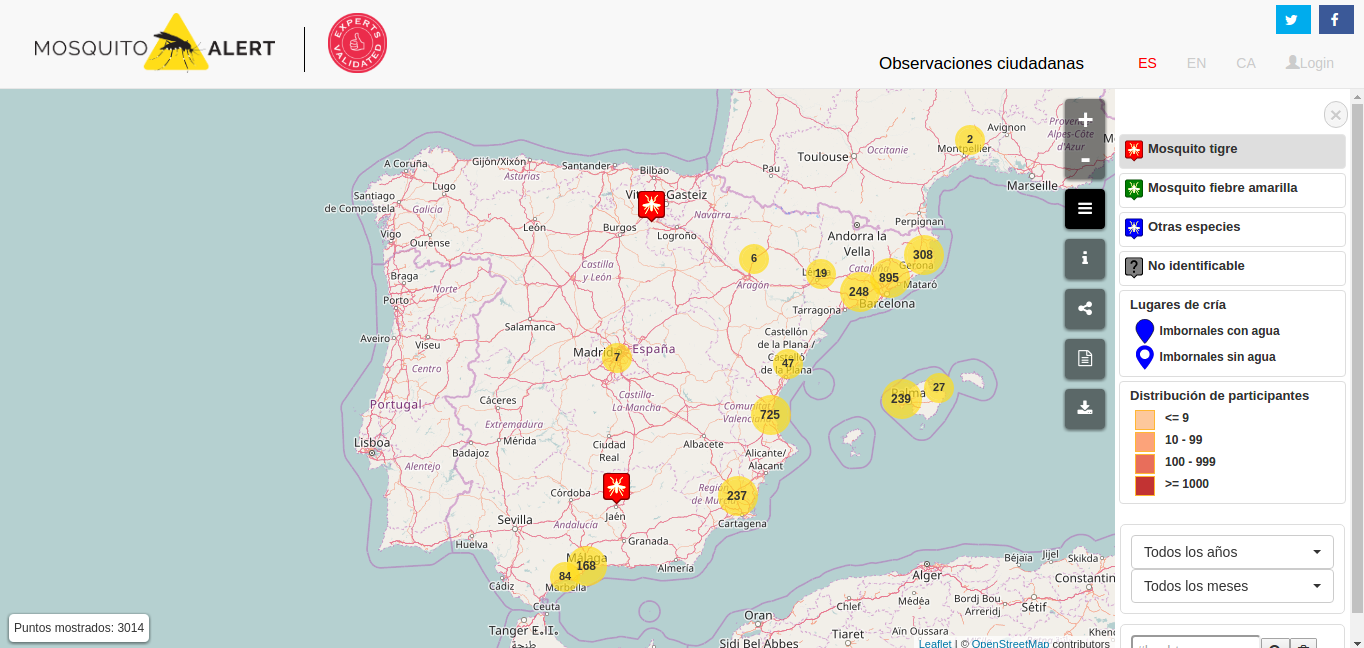
El mapa interactivo de Mosquito Alert. Fuente: mosquitoalert.com
En este post queremos compartir el reto técnico que el proyecto plantea a nivel de visualización e interacción con los datos recogidos/mostrados. Expondremos el problema y la estrategia/solución adoptada.
El problema
Hay dos requisitos en este mapa que nos hicieron plantear el diseño de una estrategia de carga y visualización de datos hecha a medida:
- Se deben mostrar todas las observaciones ciudadanas ya validadas y categorizadas por los expertos.
Esto significa que cada vez existen más datos a mostrar. Cargar toda esta información de forma disgregada en el cliente puede llegar a dificultar la escalabilidad del mapa. Había que encontrar una manera de poder cargar rápidamente los datos y a la vez mantener un elevado grado de interactividad. - La funcionalidad de filtrado de los datos es una de las principales y más usadas. Debe ser posible filtrar por la categoría a la que ha sido asignada cada observación (tigre, fiebre amarilla, otras especies y no identificables) y también de acuerdo al año y mes en que fue publicada dicha observación.
Dado que es una de las funciones más usadas, la velocidad con que se ejecutan estos filtros debía ser la mayor posible.
La solución
Optamos por considerar la agrupación de los datos en el servidor, basándonos en:
- La posición geográfica
- Los distintos años
- Los distintos meses
- La categoría de mosquito
Los 3 últimos factores de agrupación son simples y se basan en los valores posibles en cada campo. En el servidor, y mediante SQL, realizamos una consulta agrupando por todos estos campos a la vez. Algo parecido a:
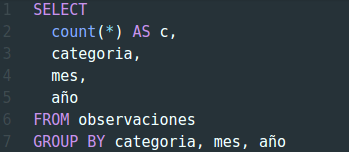
En realidad la consulta es bastante más complicada pero la hemos escrito así a título ilustrativo. Lo importante es que obtenemos un registro para cada combinación de categoría, mes y año y un recuento del número de observaciones con cada una de estas combinaciones.
Agrupar por la posición geográfica en términos absolutos resulta imposible, pero sí que podemos codificar primero los puntos mediante cuadrículas e identificar estas cuadrículas mediante un geohash.
Sin entrar en detalles, podemos decir que un geohash es un sistema de codificación que permite identificar posiciones mediante una cadena de texto simple. Y lo puede hacer con distintos niveles de precisión. Cuantos más caracteres tenga la cadena de texto más precisa es la ubicación. Más información en https://en.wikipedia.org/wiki/Geohash.
Gráficamente podemos imaginarlo como si definieramos un conjunto de mallas de distinto grueso y para cada una de ellas asignáramos a cada observación la posición del centro de la celda en la que cae dicha observación.
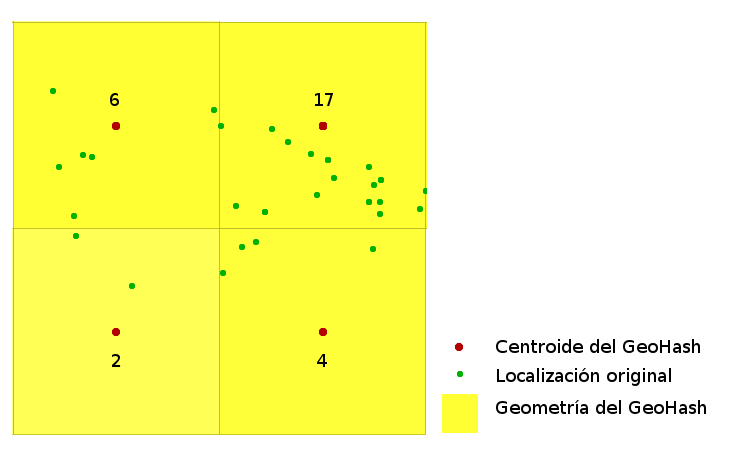
Agrupación de geometrías por geohash. Fuente: elaboración propia.
De este modo asignamos las observaciones, para cada nivel de zoom, a una celda y esto nos permite luego poder agrupar todas las observaciones de manera combinada en base a esa celda, la categoría de mosquito, el año y el mes. En PostGIS (la extensión espacial de PostgreSQL) esto resulta en una consulta SQL parecida a:
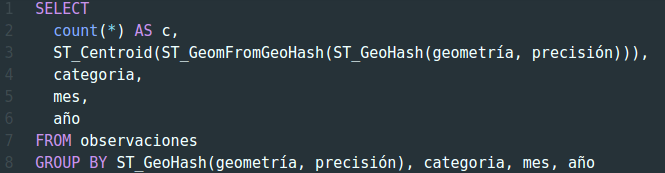
La precisión dependerá del nivel de zoom de la vista que tenemos en el mapa.
Al final, el resultado es un formato de texto JSON (https://es.wikipedia.org/wiki/JSON) parecido al siguiente:
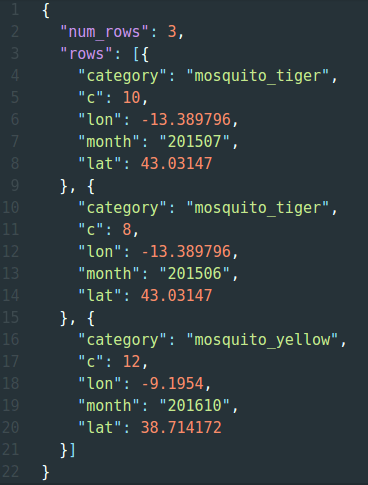
El atributo c en cada objeto indica el número de observaciones que tienen ese mismo geohash, categoría, mes y año.
La consulta usada para obtener estas agrupaciones la hemos almacenado como una vista materializada en el motor de bases de datos PostgreSQL (https://es.wikipedia.org/wiki/Vista_materializada). Esto significa que la vista no ejecuta el SQL cada vez que se consulta sino que se ejecuta una vez y se almacenan los resultados. Luego se puede programar una rutina para ir actualizando esta vista periódicamente.
Conclusiones
El enfoque planteado nos ha aportado ciertas ventajas y también algún inconveniente.
Ventajas
Entre las ventajas podemos considerar que:
- A partir de un número infinito de observaciones, nos permite definir un límite finito de datos a cargar en el cliente web. Por ejemplo, podemos definir una malla de N x N celdas, un número C de categorías y X combinaciones Año+Mes. Con esto nos aseguramos que como mucho vamos a tener un JSON con N2 * C * X registros. Esto facilita que la aplicación pueda ser escalable.
- Podemos seguir aplicando filtros directamente en el cliente, con lo que nos ahorramos tener que ir haciendo peticiones al servidor cada vez que se cambia de filtro y eso significa que:
- la velocidad de ejecución de los filtros es mayor, dado que no hay latencias ni procesado en el servidor
- no cargamos en exceso al servidor y éste muestra un mejor comportamiento ante un mayor número de usuarios consultando el mapa.
Ambos puntos (1 y 2) son divergentes. Es decir, para reducir al máximo el número de registros a cargar tenemos que reducir la cantidad de filtros. Y al revés, cuantos más filtros queramos poder ejecutar en el cliente más disgregada debe estar la información y la carga se parecerá más a los datos originales.
En este planteamiento lo que buscamos es una solución de compromiso que permita reducir al máximo el volumen de datos a cargar en el cliente sin perder capacidad de filtrado en cliente.
Inconvenientes
En cuanto a los inconvenientes nos hemos encontrado con que:
- Resulta complicado incorporar nuevos tipos de filtros en cliente y mantener las ventajas anteriormente indicadas. Cuantos más filtros queramos ejecutar en el cliente más disgregada debe estar la información y podemos llegar a un punto tal que la información se deba cargar completamente disgregada en el cliente y el planteamiento inicial pierda el sentido.
En este caso, hemos hecho una valoración de los filtros más usados habitualmente y esos son los que usamos para las agrupaciones. Los filtros menos habituales seguirán requiriendo peticiones al servidor. Es otra solución de compromiso para que las operaciones más habituales sean rápidas en detrimento de las operaciones menos habituales. - Cuando un geohash contiene una sola observación la posición asociada sigue siendo la del centroide del geohash, con lo que el usuario ve una observación en un lugar y cuando se aproxima (zoom in) ve que esa observación cambia ligeramente de ubicación (cada nivel de zoom tiene sus propios geohashes), lo que genera en el usuario una cierta confusión e inseguridad en la calidad de los datos.
Esto lo resolvimos haciendo que la consulta SQL mire primero cuántas observaciones caen en cada geohash: en caso que sólo tengamos una devolvemos la posición original de la observación y si hay más de una devolvemos el centroide del geohash.
________